Trenitalia ha da poco rilasciato la nuova versione della sua app per iOS e Android. Avendo già avuto a che fare con i meravigliosi sistemi informatici delle Ferrovie dello Stato per lo sviluppo di TrenItBot e per altri progetti, una sbirciata anche qui non poteva mancare.
Incominciamo in modo molto semplice: installiamo l’app su un dispositivo Android, impostiamo un proxy, e vediamo come l’app comunica al suo backend.
Prime piccole difficoltà
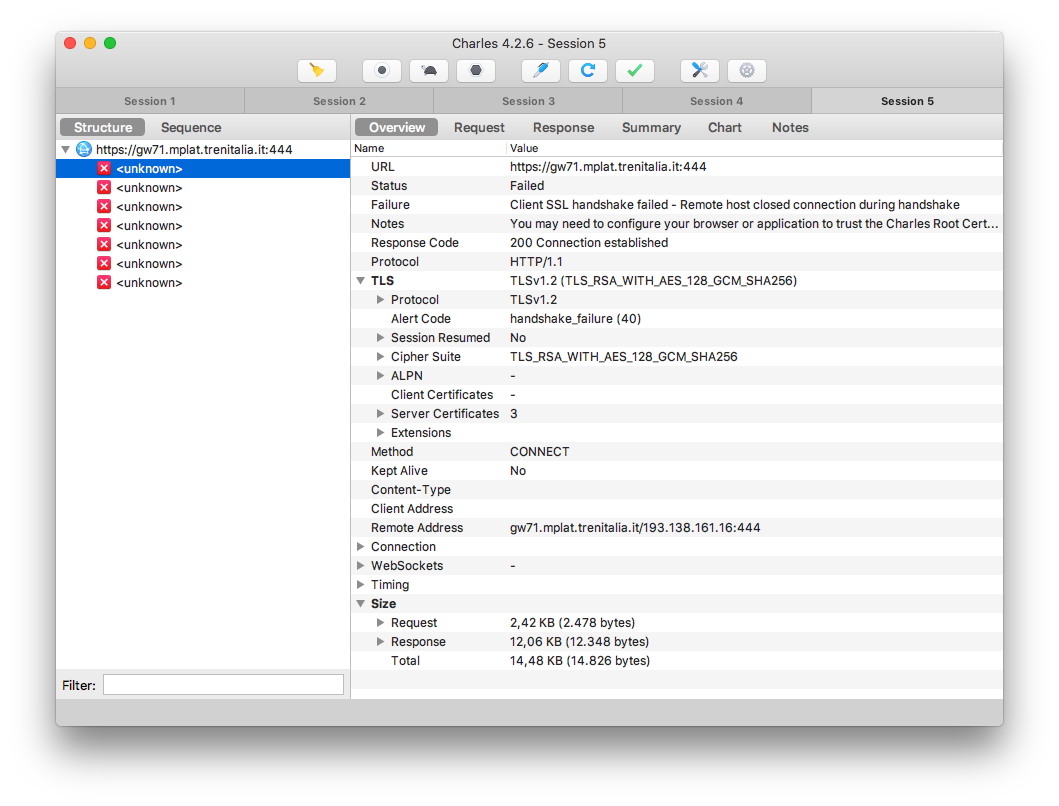
Ora sappiamo che l’indirizzo a cui l’app si collega è https://gw71.mplat.trenitalia.it:444 ma… non tutto fila sempre liscio come dovrebbe. Un errore di SSL quando il certificato del proxy è correttamente installato sul client può significare una sola cosa: l’app usa certificate pinning1. È una mossa astuta, che forse non ci si aspetterebbe dalla stessa azienda che salva le password dei suoi clienti in chiaro2 e che non usa HTTPS sulla pagina principale del suo sito3. Comunque, non sarà di certo questo dettaglio a fermarci. Le possibili vie per procedere sono due: decompilare l’app, tentare di capire in che modo effettua il ceritifcate pinning, patcharla e reinstallarla; oppure patcharla direttamente a runtime con l’aiuto di qualche modulo Xposed4.
Naturalmente scegliamo la via più comoda (che non sempre funziona, ma tanto vale provare): avendo un dispositivo su cui è già installato Xposed Framework ci basta scaricare JustTrustMe5 che si occuperà in maniera completamente automatica e trasparente di impedire a tutte le app installate di usare certificate pinning.
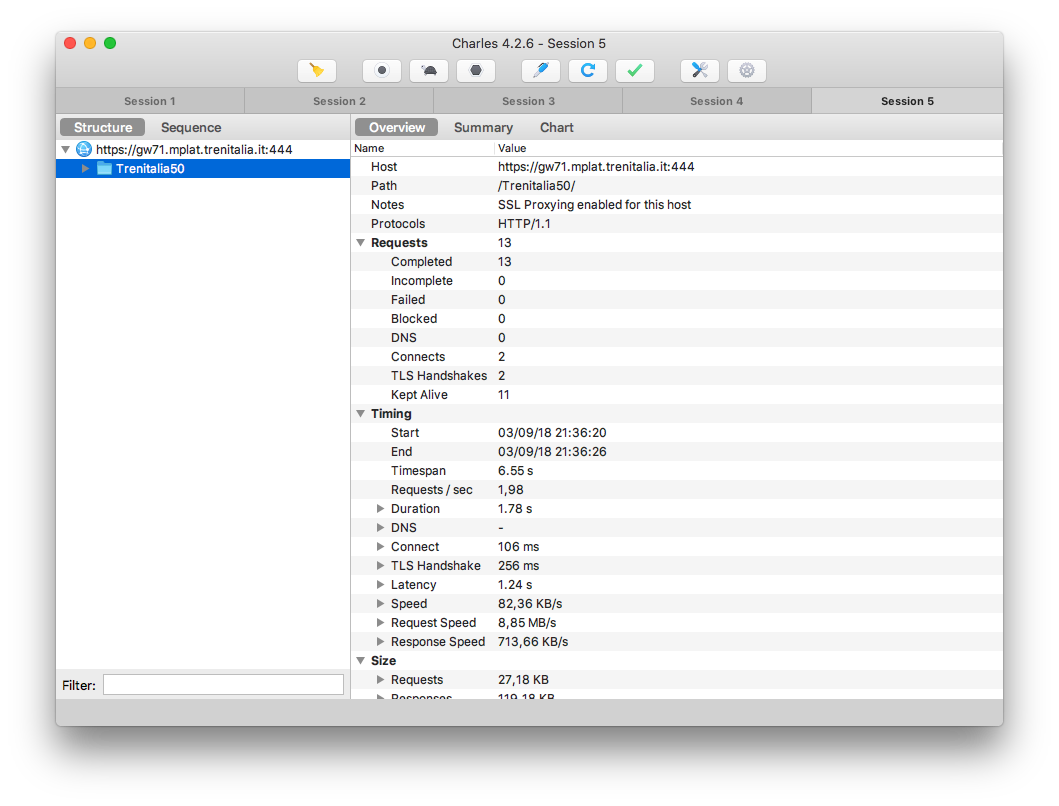 Bingo! Ora possiamo monitorare liberamente tutto il traffico tra l’app e il suo backend. Ripuliamo la sessione del proxy, chiudiamo l’app, e incominciamo a registrare tutte le richieste dal momento in cui viene riaperta.
Bingo! Ora possiamo monitorare liberamente tutto il traffico tra l’app e il suo backend. Ripuliamo la sessione del proxy, chiudiamo l’app, e incominciamo a registrare tutte le richieste dal momento in cui viene riaperta.
Nota: sembra che l’app per iOS, contrariamente a quella per Android, non utilizzi certificate pinning. Me ne sono accorto troppo tardi, ma fortunatamente questo non è stato un grosso problema.
L’autenticazione
Non sorprende il fatto che l’app debba autenticarsi con il server prima di poter essere utilizzata. Vediamo nel dettaglio le prime due richieste che vengono effettuate e le relative risposte.
Richiesta #1
POST /Trenitalia50/apps/services/api/Trenitalia/android/init HTTP/1.1
X-Requested-With: XMLHttpRequest
Accept: text/javascript, text/html, application/xml, text/xml, */*
Accept-Language: it-IT
Content-type: application/x-www-form-urlencoded; charset=UTF-8
x-wl-app-version: 5.0.1.0004
x-wl-app-details: {"applicationDetails":{"platformVersion":"7.1.0.0","nativeVersion":"2552299265","skinName":"default","skinChecksum":2573855884}}
x-wl-clientlog-unified: {"x-wl-clientlog-deviceId":"dsj32oijfds12jlk","x-wl-clientlog-appname":"Trenitalia","x-wl-clientlog-appversion":"5.0.1.0004","x-wl-clientlog-osversion":"6.0.1","x-wl-clientlog-env":"android","x-wl-clientlog-model":"Nexus 5"}
X-WL-ClientId: 390bbaa67d514345b84abfed3f8ae95943js0sak
X-WL-S-ClientId: [dati rimossi]
X-WL-Session: 94c944f2-adb7-481e-bf57-adfbc02bb405
x-wl-device-id: 4e2dd2eb-f13e-4387-8221-bbea8fb40b7c
Content-Length: 40
Host: gw71.mplat.trenitalia.it:444
Connection: Keep-Alive
User-Agent: Dalvik/2.1.0 (Linux; U; Android 6.0.1; Nexus 5 Build/M4B30Z)/Worklight/7.1.0.0
Cookie: JSESSIONID=[dati rimossi]
Cookie2: $Version=1
x-wl-analytics-tracking-id: b444eed4-7326-4f32-b5e5-909b31a3687d
isAjaxRequest=true&x=0.84104398258027315
Non male come prima richiesta. Notiamo subito una grande quantità di header, di cui molti sono usati per la profilazione dell’utente. Notiamo anche una cosa un po’ insolita (e brutta): alcuni header come x-wl-app-details contengono dei payload in formato JSON. Interessante il contenuto dell’header X-WL-S-ClientId, che purtroppo ho dovuto rimuovere per motivi di sicurezza. Si tratta di tre stringhe codificate in base64 e concatenate; anche loro contengono dati JSON e sembrano riferirsi a qualche forma di crittografia RSA. Un’altra cosa che mi ha incuriosito è il parametro x del corpo della richiesta, che sembra essere un numero reale a caso compreso tra 0 e 1, diverso ogni volta. Approfondire ulteriormente questi aspetti mi interessa poco; se qualcuno ha intenzione di mettersi in gioco e scopre qualcosa di nuovo a riguardo è sempre benvenuto.
Aggiornamento: alcuni utenti di Reddit suggeriscono una spiegazione per queste due incognite.
/u/unicoletti dice:
il parametro
xserve probabilmente ad impedire il caching della richiesta HTTP
/u/rocco88, riguardo al contenuto dell’header X-WL-S-ClientId:
Dovrebbe essere JWT: jwt.io
Vediamo ora la risposta del server:
HTTP/1.1 401 Unauthorized
Date: Sat, 25 Aug 2018 21:42:32 GMT
X-Frame-Options: SAMEORIGIN
Strict-Transport-Security: max-age=63072000; includeSubdomains; preload
X-Powered-By: Servlet/3.0
P3P: policyref="/w3c/p3p.xml", CP="CAO DSP COR CURa ADMa DEVa OUR IND PHY ONL UNI COM NAV INT DEM PRE"
WWW-Authenticate: WL-Composite-Challenge
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Cache-Control: no-cache, no-store, must-revalidate
Pragma: no-cache
Content-Length: 166
Set-Cookie: WL_PERSISTENT_COOKIE=4a8c58c8-0230-4fa3-98dc-fd870f89f147; Expires=Sun, 25-Aug-19 21:42:32 GMT; Path=/Trenitalia50
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
Keep-Alive: timeout=10, max=99
Content-Type: application/json; charset=UTF-8
Content-Language: en-US
Connection: keep-alive
/*-secure-
{"challenges":{"wl_antiXSRFRealm":{"WL-Instance-Id":"8e22b68ac66c4624a9b4j8gf3f"},"wl_deviceNoProvisioningRealm":{"token":"3dac410d695e4cd18f4782829y"}}}*/
Ci sono solo un paio di cose da notare:
- il server restituisce un codice
401 Unauthorized. È perfettamente comprensibile visto che l’app non si è ancora autenticata; - il server comunica all’app la modalità di autenticazione tramite l’header
WWW-Authenticate; - il corpo della risposta è un payload JSON racchiuso in un tag del tipo
/*-secure-[payload]*/. Sarà una seccatura dover ripulire ogni volta le risposte da questi inutili tag.
Da questo momento il client ha tutte le informazioni necessarie per potersi autenticare sul server; infatti l’app invia immediatamente una seconda richiesta.
Richiesta #2
Questa seconda richiesta è simile alla prima eccetto per due header aggiuntivi:
WL-Instance-Id: 8e22b68ac66c4624a9b4j8gf3f
Authorization: {"wl_deviceNoProvisioningRealm":{"ID":{"token":"3dac410d695e4cd18f4782829y","app":{"id":"Trenitalia","version":"5.0.1.0004"},"device":{"id":"4e2dd2eb-f13e-4387-8221-bbea8fb40b7c","os":"6.0.1","model":"Nexus 5","environment":"android"},"custom":{}}}}
Naturalmente si tratta degli header rispettivamente di sessione e di autenticazione. I valori di entrambi ci sono stati comunicati dal server nel corpo prima richiesta.
Anche la risposta del server è analoga alla precedente, ma questa volta riceviamo un codice 200 OK a conferma del fatto che ci siamo autenticati con successo.
Richieste successive
Ora ci chiediamo: quali header sono essenziali per rimanere autenticati e quali invece non servono? E anche: quali header sono obbligatori (pena codice 500 Internal Server Error) e quali sono inutili? Utilizziamo gli strumenti del proxy per inviare la richiesta precedente più volte, ogni volta rimuovendo un header, fino a quando otteniamo un errore. Con questo procedimento riusciamo a trovare la richiesta con il minimo numero di header che vada comunque a buon fine:
POST /Trenitalia50/apps/services/api/Trenitalia/android/init HTTP/1.1
x-wl-app-version: 5.0.1.0004
WL-Instance-Id: hr6dors9prb2krenhap5ni2qvk
Host: gw71.mplat.trenitalia.it:444
Content-Length: 634
Content-Type: application/x-www-form-urlencoded
Molto meno incasinato di prima! Sostanzialmente oltre agli header standard e ai cookie (che devono essere sempre preservati) ce ne sono solo due da aggiungere obbligatoriamente: x-wl-app-version (la versione dell’app), e WL-Instance-Id, l’ID di sessione di cui abbiamo parlato prima. Anche i due parametri della richiesta isAjaxRequest e x possono essere omessi senza conseguenze.
Conclusioni
Riassumendo, il flusso di autenticazione che dovremo seguire è il seguente:
- impostiamo solamente l’header
x-wl-app-versione facciamo una richiesta POST; - otteniamo una risposta con codice
401, il corpo contiene il valore dell’headerWL-Instance-Ide il token di autenticazione; - aggiungiamo l’header
WL-Instance-Ide l’headerAuthorization, la cui struttura è indicata nella richiesta #2; - il server conferma l’avvenuta autenticazione con un codice
200; - da questo momento tutte le richieste dovranno avere tra gli header solamente
x-wl-app-versioneWL-Instance-Id6.
Apriamo una parentesi per notare come questo meccanismo di autenticazione renda immediatamente riconoscibile la piattaforma su cui è stata sviluppata l’app: si tratta di IBM Worklight (ecco cosa significa quel WL costantemente presente negli header!). La cosa non sorprende visto che Trenitalia si è basata a lungo su IBM per i propri server e solo negli ultimi anni ha incominciato a migrare alcuni servizi verso Microsoft. Si spiega anche il look da webapp dell’applicazione, che in effetti è scritta in HTML5 e JavaScript. Purtroppo Worklight non è piattaforma ben nota e documentata su internet, e questo rende tutto più complicato visto che dovremo cavarcela da soli.
Comunque, ora che sappiamo come funziona l’autenticazione client-server possiamo analizzare ogni richiesta effettuata dall’app e saremo anche in grado di riprodurla. Prima di addentrarci nelle varie funzionalità dell’applicazione, però, può essere utile e interessante fare una piccola digressione su com’è fatta la banca dati degli orari di Trenitalia a cui questa attinge (come vedremo, tramite opportuni adattatori).
La banca dati di Trenitalia
La procedura di creazione di un orario ferroviario è estremamente complessa e oltre Trenitalia coinvolge RFI, azienda del gruppo FS che si occupa della gestione dell’infrastruttura. Quest’ultima raccoglie le richieste delle diverse Imprese Ferroviarie, progetta le tracce con gli orari, il percorso e la composizione di ogni singolo treno, quindi archivia il tutto in un database relazionale di Microsoft Access denominato Treno Nazionale. Questo database, integrato con ulteriori informazioni (come i numeri dei binari) provenienti dalle direzioni compartimentali di tutto il territorio, alimenta la produzione dei quadri orario in stazione, il motore di ricerca del sito di Trenitalia, ViaggiaTreno7, eccetera.
Esistono quindi molti servizi che si interfacciano a questa grossa banca dati, e per di più ogni servizio usa il suo protocollo e necessita di informazioni in un determinato formato. ViaggiaTreno per esempio utilizza un API di tipo REST per cui è stato costruito un opportuno adattatore, mentre altri potenziali client che usano un altro protocollo necessitano di un adattatore diverso. Gli adattatori non fanno altro che mettere in comunicazione due software che parlano lingue diverse.
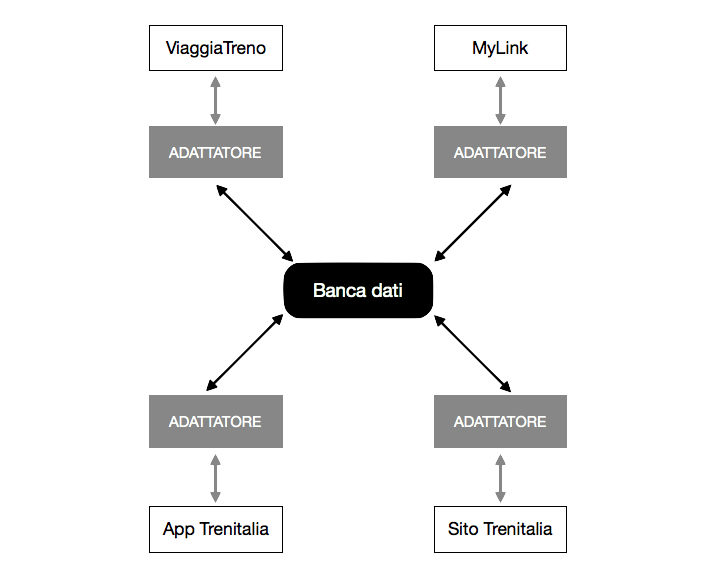
Bisogna anche sottolineare che gli adattatori (almeno in teoria) selezionano dalla banca dati solo i dati che effettivamente servono all’applicazione per cui sono stati costruiti. Nella realtà dei fatti questo non è sempre vero: basta vedere l’enorme mole di dati che viene restituita dall’API di ViaggiaTreno8 per accorgersi che molti di questi rimangono inutilizzati dal frontend. Per esempio i codici interni dei binari sono completamente inutili e non vengono neanche menzionati nel codice sorgente del sito; tuttavia sono presenti tra le informazioni che vengono recuperate e messe a disposizione dall’adattatore.
Altri dati vengono invece filtrati o modificati nel passaggio dalla banca dati al client; è questo il caso delle località, che in ViaggiaTreno sono limitate alle stazioni che effettuano servizio viaggiatori (non compaiono le stazioni per i treni merci, i posti di movimento, i bivi e le località di passaggio). Il nome delle stazioni viene reso leggermente più comprensibile rispetto a come è salvato in Treno Nazionale, dove è limitato a 16 caratteri e presenta abbreviazioni e ambiguità spesso indecifrabili. Infine il codice della stazione viene prefissato dal carattere S oppure N a seconda che si tratti di una stazione gestita da RFI o da FerrovieNord.
L’API e le richieste
Ho analizzato approfonditamente tutte le richieste che costituiscono il cuore dell’applicazione: orari, tariffe, offerte, stato dei treni in tempo reale, ecc. Ho prodotto una documentazione empirica basata su ciò che ho scoperto, e ho scritto un wrapper in Python che permette a chiunque di utilizzare parte dell’API dell’app in modo semplice. Trovate tutto sul mio repository di GitHub e sulla relativa Wiki. Qui di seguito vorrei invece soffermarmi su alcuni aspetti più discorsivi e piacevoli anche per chi non è interessato a una mera documentazione tecnica.
Innanzitutto notiamo che tutte le richieste non-meta, cioè che non riguardano l’applicazione stessa o il suo funzionamento, usano un unico endpoint:
POST /Trenitalia50/apps/services/api/Trenitalia/android/query HTTP/1.1
Qui emerge molto nitidamente il ruolo esterno del server a cui sono inviate le richieste, che non entra mai nel merito dei dati sui treni e che quindi non si interfaccia in nessun modo alla banca dati di Trenitalia. Invece, l’app invia al server tre informazioni fondamentali tramite il corpo della POST: l’adattatore che ha bisogno di contattare; l’informazione che necessita dalla banca dati; i dati in formato JSON che verranno utilizzati per interrogare la banca dati. A questo punto il server contatta l’adattatore in questione e gli passa i dati come fossero una scatola nera, ignorando completamente cosa siano o cosa contengano. Sarà l’adattatore ad aprire la scatola e a guardarci dentro.
Il server che si appoggia effettivamente alla banca dati esegue Microsoft IIS e comunica tramite il protocollo SOAP9. Anche questo è reso evidente dalle risposte del server alle varie richieste. Allora all’adattatore tocca il compito di leggere i parametri che ha ricevuto, rielaborarli in modo da ottenere un envelope secondo il protocollo SOAP, e inoltrare il risultato all’ultimo server della catena. Questo provvederà ad ottenere le informazioni dalla banca dati, a restituirle all’adattatore, che quindi le riconvertirà in JSON e le restituirà al backend dell’app.
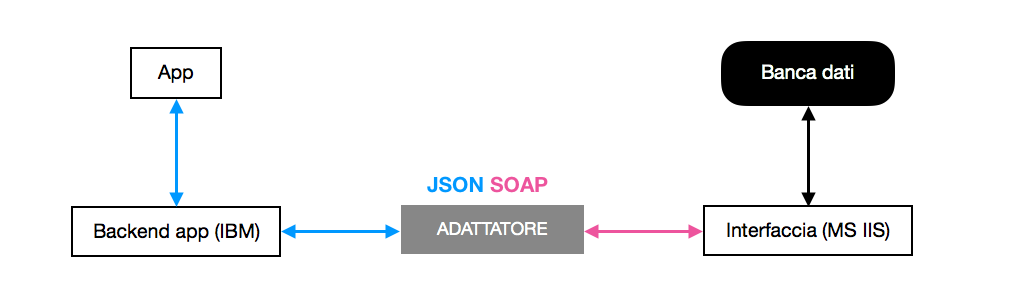
Per qualcuno si tratterà sicuramente di un’implementazione brutta, specialmente se vista dall’applicazione e senza avere una prospettiva generale. Tuttavia sembra una scelta piuttosto logica e sensata se si vuole avere un sistema che sia il più possibile modulare. Ciò non toglie che tutte le risposte ricevute dall’API abbiano un enorme overhead di informazioni inutili, che rendono macchinosa l’elaborazione delle risposte (specialmente senza avere una documentazione sottomano).
A questo si aggiungono alcune incoerenze a cui bisogna prestare una certa attenzione:
- a volte la risposta (in JSON) è racchiusa in tag di tipo
/*-secure-[payload]*/, altre volte no; - in alcuni campi la data inviata o ricevuta contiene un offset rispetto a UTC per determinare il fuso orario; in altri campi invece la data è naive;
- in alcuni casi il valore
nullviene utilizzato normalmente, in altri casi è sostituito da un dizionario:{"nil": true}; - spesso, ma non sempre, gli interi sono passati come stringa.
Approfondimenti sui dati
Le stazioni
La UIC10 specifica i codici identificativi di ogni località a livello internazionale; si tratta di codici numerici da 1 a 5 cifre detti ENEE11, e sono gli stessi restituiti dal backend di ViaggiaTreno. Sono invece detti RICS12 i codici a 2 cifre che identificano le compagnie ferroviarie. Ogni coppia (codice RICS, codice ENEE) identifica univocamente una località a livello internazionale. Naturalmente località in questo contesto è un termine che generalizza il concetto di stazione, includendo anche bivi, posti di movimento, ecc.
Trenitalia utilizza perciò come ID delle stazioni una combinazione di questi due identificativi; in particolare per la sua app sembra che il codice di ogni stazione sia costituito dal codice RICS concatenato al codice ENEE esteso con eventuali zeri fino a 7 cifre. Per esempio, il codice RICS delle FS è 83; il codice ENEE della stazione di Milano Centrale è 1700; il corrispondente ID restituito dall’API dell’app di Trenitalia è 830001700.
In realtà esistono delle eccezioni: si tratta di alcune località toscane di cui nessuna sembra corrispondere a una stazione ferroviaria, e che quindi non hanno un codice ENEE. Non sono riuscito a capire quale sia il ruolo di queste località, che sono riconoscibili perché il loro ID è compreso tra 835118101 e 835118359. Forse si tratta di fermate per autobus, ma il motivo per cui siano presenti qui non mi è chiaro.
Le informazioni in tempo reale
L’app di Trenitalia permette di cercare un treno e di visualizzare informazioni in tempo reale come fermate, ritardi, binari, ecc. Naturalmente queste informazioni provengono dalla stessa fonte di dati di ViaggiaTreno, tuttavia ci sono delle differenze importanti nei dati che vengono restituiti. Innanzitutto dovrebbe ormai essere chiaro e non dovrebbe stupire il fatto che i nomi delle stazioni siano scritti in maniera diversa. Gli ID delle stazioni sono i soliti codici ENEE sprovvisti del prefisso S o N aggiunto da ViaggiaTreno e senza zeri di padding. Per ogni stazione vengono anche restituite le relative coordinate geografiche, se presenti nel database.
Molte informazioni presenti in ViaggiaTreno qui sono assenti:
- il percorso dei treni soppressi;
- eventuali fermate soppresse o straordinarie;
- l’orientamento del treno;
- l’operatore del treno (Trenitalia, Trenord, ecc.);
- la tipologia di treno (anche se compaiono solo treni viaggiatori);
- i cambi di numerazione;
- eventuale origine o destinazione estera con relativi orari.
Ma qui c’è un’informazione in più rispetto a ViaggiaTreno, che peraltro sorprende molto vedere: nell’elenco di fermate di ogni treno sono incluse anche tutte le località intermedie per cui il treno transita senza fermarsi. Questi dati sono presenti e utilizzati anche da ViaggiaTreno per il calcolo del ritardo e per mostrare l’ora e il luogo di ultimo rilevamento, tuttavia non sono restituiti dall’API. In questo caso invece è disponibile l’intero percorso del treno, comprensivo degli orari di transito previsti, e i dati mostrati all’utente sono filtrati direttamente dall’interfaccia dell’applicazione.
L’API a disposizione di tutti
Ho già menzionato il repository di GitHub che ho creato contestualmente a questo post. Il wrapper in Python dell’API è a disposizione di chiunque voglia studiarne il codice o per chi voglia semplicemente avere a disposizione un’interfaccia comoda per i propri progetti.
Chi invece non si accontenta degli endpoint supportati dal mio codice (che non è assolutamente completo) può visitare la Wiki e studiare direttamente il funzionamento dell’API, magari sporcandosi le mani con un proxy per vedere con i propri occhi ciò che io ho documentato. Sarebbe poi molto interessante se qualcuno decidesse di crearsi un proprio wrapper alternativo o – ancora meglio – di completare il mio con gli endpoint e tutto ciò che manca. A tal proposito sono sempre benvenute le pull request che possano integrare o estendere il mio lavoro.
-
https://security.stackexchange.com/questions/29988/what-is-certificate-pinning ↩︎
-
http://plaintextoffenders.com/post/30583672228/trenitaliacom-italian-railway-password-change ↩︎
-
http://repo.xposed.info/module/de.robv.android.xposed.installer ↩︎
-
L’header
Authorizationviene utilizzato solo una volta per eseguire l’autenticazione; non deve essere inserito per le richieste successive. ↩︎ -
https://github.com/bluviolin/TrainMonitor/wiki/API-del-sistema-Viaggiatreno ↩︎